As Incident Response defenders, we will always be interested to know that how the attackers gain as much information about the target without ever touching the Organization and infrastructure or not even engaging with an insider. Before exploiting any networks it would be good to initially compromise the insider through Phishing or any social engineering techniques further which could be used as a foundation to the Organization the attacker is trying to breach.
Here in this topic, we will focus on the few points that can discuss network targets on Domains, IP address, operating system and gathering personal information on email addresses, names, Job titles, location, and Employer details, etc., so these details will be the information gathered initially by attackers before starting to penetrate the target networks.
Let’s begin to understand,
Stage 1
Network Mapping
In the first place, it’s always necessary, to begin with, the discovery process, which is not possible to directly tracking the target from online. Most of the Organizations will have a name and primary domain name to the Organizations which is used for email communication. So it will be a better place to start with. Information required is to get started with the name for example Organization Name: Sony Interactive Entertainment and domain name: (https://www.sie.com/).
Based on the Company name and domain name we can have basic information like Key people of the Organization, Headcount of the employees, and target business the company is running. And few more details can be collected from Company LinkedIn Profiles which will provide a background of the organizations.

Domain Names
After collecting the basic background information, domain and subdomains are the next steps. In addition to the domain name, we can also find Subdomains using WHOIS reverse lookups. WHOXY is one of the website databases which provides information about the subdomains registered particular to the target’s main domain.

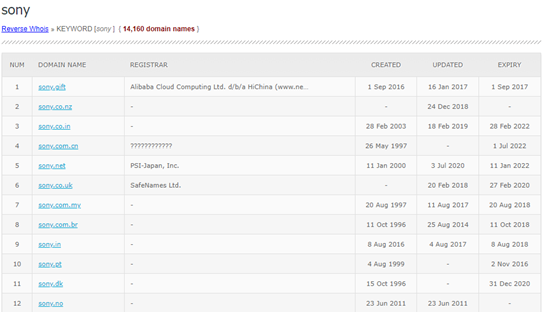
At this stage, we can collect the necessary information of the domains registered and move to the next step of Subdomain discovery. It is good that companies follow the one variants of names for their domain registration, which is easy to get reverse WHOIS details as well.
Checking Subdomains
As there are many tools available to perform subdomain searches like DNS dumpster and Netcraft will result from the decent number of information of DNS servers, MX records, TXT records, etc, of the target domain. And TLS certificates can also be pulled from the website Censys.io which will reveal the additional Subdomain which is not yet been recorded. Usually, the subdomains can be pulled from the certificate alternate names of the domain.
For example, censys certificate search for “Google.com” returned with the below results of subdomains of google domain as,
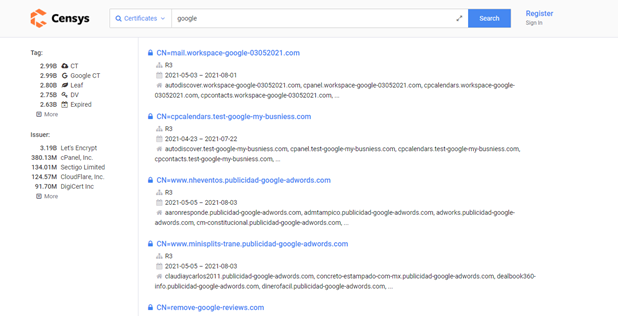
However, the certificates tend to give fast search results of the subdomains of the related target domain but sometimes the dataset will return unrelated results which mostly confuses the search query. In addition to that, the certificate transparency project which is offered by Google can give more subdomain information.
IP address and DNS records
As we all know that big list domain names subdomain name will be resolved to IP addresses. DNS records are very useful in such as A records will provide IP addresses and some interesting information. Automating DNS resolutions, scripts can be handy, but for manual search dnsstuff.com is an interesting to check DNS query records and domain ownerships details.
Stage 2
Contact Discovery
This is the second stage where we need to find the personnel of the target organization. Along with that, we have to find the target email IDs from the known search engines like google, yahoo, Bing, etc. associated with the purpose of their business. It is intended for sales and marketing people to collect it, but anybody can collect and use information like phone number, email address, job titles which can be used for social engineering attacks.
Email Address
Email address is an open opportunity for phishing campaigns and password spraying techniques. Most likely collected information still now is not that interesting. This also indicates that how long the employee worked in the organization (assuming that has not left the company at his point of the stage) and it will also be useful in knowing services that the company is using internally. In case, if the old passwords are available they can be reused for business accounts.
Looking for the email address through paste site (e.g. Pastebin, ghostbin, slexy) can give valuable information. HaveIBeenPWned can also be used to search the email address. It is always important to note down the information you have got because it might vanish after some time and could become a dead end of the search.
Social Media search
It is a generally good idea to search the information from Social media sites that can be useful in the intelligence-gathering process. However, it is not difficult to collect the information from Twitter and LinkedIn profile which shares dozens of info reconnaissance.
For example: searching the company’s LinkedIn profiles will give you a site: linkedin.com COMPANY in google search will return details includes email address, job titles. Locations etc.
Always start with Twitter accounts of the target which reveals the recent activity of the user and shows whether it exists or not and collect follower information, count, location, biography, and real name, etc., Assuming that we received a handful of legitimate information on the accounts and proceed further.
Stage 3
Cloud
We have come to the third stage where a couple more details need to be collected and round up with the available data.
File Digging
Most of the corporates websites have a list of files left behind their domains. These must be accumulated from years together and includes the Word document file, PDF files, and other misc. files. By performing a basic google search with strings: site: company.com filetype: pdf will reveal them to download. These files must be uploaded intentionally for the narrower audience without realizing that someone can download them, through the search index of the domain website it can found to download.

Bucket Hunting
First, let us understand what is the term “Bucket” means, as the internet grows and all services now are running in cloud platforms “server-less” technologies which companies nowadays facing issues with cloud security through misconfigurations.
Few Common bucket uses:
- Publicly accessible data – Google LandSat
- Phone or Web App storage – Instagram, Homeroom, Cluster
- Websites – RottenTomatoes, IMDB
Bucket hunting is a very popular topic for hunting today, but you can check for Digital Ocean Spaces which has launched its services similar to S3 and called it Spaces. Digital Oceans has deferred to the industry standards, S3 bucket and Spaces operate similarly and tools for hunting bucket and made available to work with Digital Ocean’s Space as well.
Stage 4
Reporting and Automation Process
The final stage to report all these findings to report and automating, as this would be difficult for every project to perform all the previous stages for every new project. If you are part of a Security defender, Penetration tester, or bug bounty hunter who’s looking to perform continuous asset discovery, this is not all easy to run individual tools every time for the reconnaissance phase.
The above process has been automated and everything mentioned above is a tool called ODIN developed by Christopher Maddalena from the SpecterOps team.
The tool can be found here: https://github.com/chrismaddalena/ODIN

Conclusions:
Above mentioned process doesn’t give all complete information about an Organization. Depending on the organization size Intelligence gathering can be more complex once you start dealing with. But you have trust that you have gathered some possible information which served well.
Online available resources data suggests that an outsider can gain as much as information from the process detailed above. It’s easy to find the weak spots of the target organization.
OSINT is an Organic framework which is focused on gathering the information which people can use it for free from OSINT resources.